Configuration¶
The installation section describes compile-time options available to configure the zfp software. This section provides additional, more detailed documentation of the rationale for and potential impact of these settings, including portability of zfp compressed streams across builds with different configuration settings.
Unfortunately, zfp streams do not currently embed any information with regards to the settings configured for the stream producer, though some settings for a given zfp build can be determined programmatically at run time. We hope to rectify this in future versions of zfp.
The following sections discuss configuration settings in detail:
Word Size¶
zfp bit streams are read and written one word at a time. The size of a
word is a user-configurable parameter (see BIT_STREAM_WORD_TYPE
and ZFP_BIT_STREAM_WORD_SIZE) set at compile time, and may be one
of 8, 16, 32, and 64 bits. By default, it is set to 64 bits as longer words
tend to improve performance.
Regardless of the word size, the zfp bitstream buffers one
word of input or output, and each call to stream_write_bits() to
output 1 ≤ n ≤ 64 bits conceptually appends those n bits to the
buffered word one at a time, from least to most significant bit. As soon as
the buffered word is full, it is written to the output as a whole word in the
native endian byte order of the hardware platform. Analogously, when reading
a bit stream, one word is fetched and buffered at a time, and bits are
returned by stream_read_bits() by consuming bits from the buffered
word from least to most significant bit. This process is illustrated in
Fig. 1.
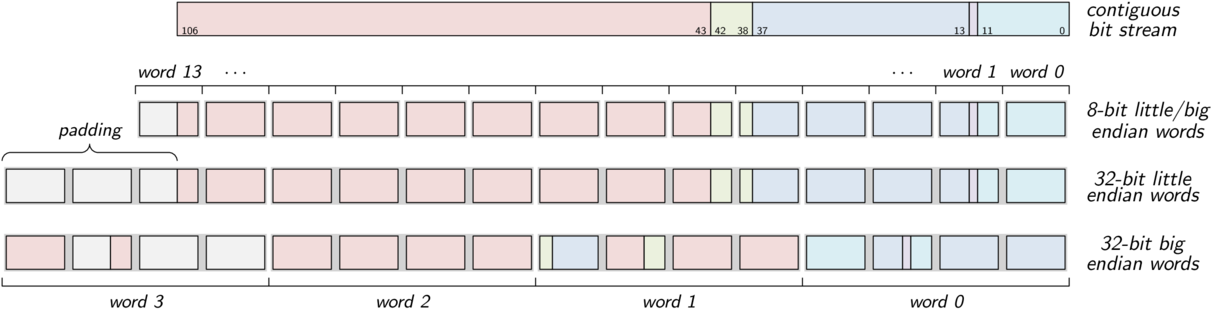
Fig. 1 Top: Bit stream written as (from right to left) five sequences of length 12 + 1 + 25 + 5 + 64 = 107 bits. Bottom: Bit stream written as 8-bit and 32-bit words in little and big endian byte order. The two little endian streams differ only in the amount of padding appended to fill out the last (leftmost) word.¶
Determining Word Size¶
After zfp has been built, it is possible to query the word size that was
chosen at compile time. Programmatically, the constant
stream_word_bits as well as the function stream_alignment()
give the word size in bits. One may also glean this information from the
command line using the testzfp executable.
Unfortunately, zfp currently does not embed in the compressed stream any information regarding the word size used. If Stream Headers are used, one may at best infer little- versus big-endian byte order by inspecting the bytes stored one at a time, which begins with the characters ‘z’, ‘f’, ‘p’. On big-endian machines with word sizes greater than 8, those first bytes will appear in a different order.
Rate Granularity¶
The word size dictates the granularity of rates (in bits/value) supported by zfp’s compressed-array classes. Each d-dimensional compressed block of 4d values is represented as a whole number of words. Thus, smaller words result in finer rate granularity. See also FAQ #12.
Performance¶
Performance is improved by larger word sizes due to fewer reads from and writes to memory, as well as fewer loop iterations to process the up to 64 bits read or written. If portability across different-endian platforms is not necessary (e.g., for persistent storage of compressed streams), then we suggest using as word size the widest integer size supported by the hardware (usually 32 or 64 bits).
Execution Policy¶
The CUDA back-end currently ignores the word size specified at compile time and always use 64-bit words. This impacts portability of streams compressed or decompressed using these execution policies. We expect future support for user-configurable word sizes for CUDA. In contrast, both the serial and OpenMP back-ends respect word size.
Portability¶
When the chosen word size is larger than one byte (8 bits), the byte order employed by the hardware architecture affects the sequence of bytes written to and read from the stream, as each read or written word is broken down into a set of bytes. Two common conventions are used: little endian order, where the least significant byte of a word appears first, and big endian order, where the most significant byte appears first. Therefore, a stream written on a little-endian platform with a word size greater than 8 bits will not be properly read on a big-endian platform and vice versa. We say that such zfp streams are endian-dependent and not portable.
When the word size is one byte (8 bits), on the other hand, each word read or written is one byte, and endianness does not matter. Such zfp streams are portable.
Warning
For compressed streams to be portable across platforms with different byte order, zfp must be built with a word size of 8 bits.
When using the zfp bitstream API, it is possible to write up to 64 bits at a time. When the word size is 8 bits and more than 8 bits are written at a time, zfp appends bits to the output in little-endian order, from least to most significant bit, regardless of the endianness of the hardware architecture. This ensures portability across machines with different byte order, and should be the preferred configuration when cross-platform portability is needed. For this reason, the zfp compression plugin for the HDF5 file format, H5Z-ZFP, requires zfp to be built with an 8-bit word size.
On little-endian hardware platforms, the order of bytes read and written is
independent of word size. While readers and writers may in principle employ
different word sizes, it is rarely safe to do so. High-level API functions
like zfp_compress() and zfp_decompress() always align the
stream on a word boundary before returning. The consequences of this are
twofold:
If a stream is read with a larger word size than the word size used when the stream was written, then the last word read may extend beyond the memory buffer allocated for the stream, resulting in a buffer over-read memory access violation error.
When multiple fields are compressed back-to-back to the same stream through a sequence of
zfp_compress()calls, padding is potentially inserted between consecutive fields. The amount of padding is dependent on word size. That is,zfp_compress()flushes up to a word of buffered bits if the stream does not already end on a word boundary. Similarly,zfp_decompress()positions the stream on the same word boundary (when the word size is fixed) so that compression and decompression are synchronized. Because of such padding, subsequentzfp_decompress()calls may not read from the correct bit stream offset if word sizes do not agree between reader and writer. For portability, the user may have to manually insert additional padding (usingstream_wtell()andstream_pad()on writes,stream_rtell()andstream_skip()on reads) to align the stream on a whole 64-bit word boundary.
Warning
Even though zfp uses little-endian byte order, the word alignment imposed
by the high-level API functions zfp_compress() and
zfp_decompress() may result in differences in padding when different
word sizes are used. To guarantee portability of zfp streams, we recommend
using a word size of 8 bits (one byte).
On big-endian platforms, it is not possible to ensure portability unless the word size is 8 bits. Thus, for full portability when compressed data is exchanged between different platforms, we suggest using 8-bit words.
Testing¶
The zfp unit tests have been designed only for the default 64-bit word size. Thus, most tests will fail if a smaller word size is used. We plan to address this shortcoming in the near future.
Rounding Mode¶
In zfp’s lossy compression modes, quantization is usually employed to
discard some number of least significant bits of transform coefficients.
By default, such bits are simply replaced with zeros, which is analogous
to truncation, or rounding towards zero. (Because zfp represents
coefficients in negabinary, or base minus two, the actual effect of
such truncation is more complicated.) The net effect is that compression
errors are usually biased in one direction or another, and this bias
further depends on a value’s location within a block (see FAQ
#30). To mitigate this bias, other rounding
modes can be selected at compile time via ZFP_ROUNDING_MODE.
Supported Rounding Modes¶
As of zfp 1.0.0, the following three rounding modes are available:
-
ZFP_ROUND_NEVER¶
This is the default rounding mode, which simply zeros trailing bits analogous to truncation, as described above.
-
ZFP_ROUND_FIRST¶
This mode applies rounding during compression by first offsetting values by an amount proportional to the quantization step before truncation, causing errors to cancel on average. This rounding mode is essentially a form of mid-tread quantization.
Although this is the preferred rounding mode as far as error bias cancellation is concerned, it relies on knowing in advance the precision of each coefficient and is available only in fixed-precision and -accuracy compression modes.
Note
ZFP_ROUND_FIRST impacts the both the bits stored in the compressed
stream and the decompressed values.
-
ZFP_ROUND_LAST¶
This mode applies rounding during decompression by offsetting decoded values by an amount proportional to the quantization step. This rounding mode is essentially a form of mid-riser quantization.
This rounding mode is available in all compression modes but tends to be less effective at reducing error bias than
ZFP_ROUND_FIRST, though more effective thanZFP_ROUND_NEVER.
Note
As ZFP_ROUND_LAST is applied only during decompression, it has
no impact on the compressed stream. Only the values returned from
decompression are affected.
The rounding mode must be selected at compile time by setting
ZFP_ROUNDING_MODE, e.g., using GNU make or CMake commands
make ZFP_ROUNDING_MODE=ZFP_ROUND_NEVER
cmake -DZFP_ROUNDING_MODE=ZFP_ROUND_NEVER ..
In general, the same rounding mode ought to be used by data producer and
consumer, though since ZFP_ROUND_NEVER and
ZFP_ROUND_FIRST decode values the same way, and since
ZFP_ROUND_NEVER and ZFP_ROUND_LAST encode values the
same way, there really is only one combination of rounding modes that should
be avoided:
Warning
Do not compress data with ZFP_ROUND_FIRST and then decompress
with ZFP_ROUND_LAST. This will apply bias correction twice and
cause errors to be larger than necessary, perhaps even exceeding any
specified error tolerance.
Error Bounds and Distributions¶
The centering of errors implied by ZFP_ROUND_FIRST and
ZFP_ROUND_LAST reduces not only the bias but also the maximum
absolute error for a given quantization level (or precision). In fact, the
reduction in maximum error is so large that it is possible to reduce precision
of transform coefficients by one bit in
fixed-accuracy mode while staying within the
prescribed error tolerance. (Note that the same precision reduction applies
to expert mode when zfp_stream.minexp is
specified.) In other words, one may boost the compression ratio for a given
error tolerance. Viewed differently, the error bound can be tightened such
that observed errors are closer to the tolerance.
To take advantage of such a tighter error bound and improvement in compression
ratio, one should enable ZFP_WITH_TIGHT_ERROR at compile time.
This macro, which should only be used in conjunction with
ZFP_ROUND_FIRST or ZFP_ROUND_LAST, reduces precision
by one bit in fixed-accuracy mode, thus
increasing error while decreasing compressed size without violating the
error tolerance.
Warning
Both producer and consumer must use the same setting of
ZFP_WITH_TIGHT_ERROR. Also note that this setting makes
compressed streams incompatible with the default settings of zfp and
existing compressed formats built on top of zfp, such as the
H5Z-ZFP HDF5 plugin.
For more details on how rounding modes and tight error bounds impact error, see FAQ #30.
Performance¶
The rounding mode has only a small impact on performance. As both
ZFP_ROUND_FIRST and ZFP_ROUND_LAST require an offset to
be applied to transform coefficient, they incur a small overhead relative to
ZFP_ROUND_NEVER, where no such corrections are needed.
Execution Policy¶
ZFP_WITH_TIGHT_ERROR applies only to
fixed-accuracy and expert
mode, neither of which is currently supported by the CUDA execution policy.
Therefore, this setting is currently ignored in CUDA but will be supported
in the next zfp release.
Portability¶
As ZFP_WITH_TIGHT_ERROR determines the number of bits to write
per block in fixed-accuracy mode, the producer
and consumer of compressed streams must be compiled with the same setting
for streams to be portable in this compression mode.
Testing¶
The zfp unit tests have been designed for the default rounding mode,
ZFP_ROUND_NEVER. These tests will in general fail when another
rounding mode is chosen.
Subnormals¶
Subnormal numbers (aka. denormals) are extremely small floating-point numbers (on the order of 10-308 for double precision) that have a special IEEE 754 floating-point representation. Because such numbers are exceptions that deviate from the usual floating-point representation, some hardware architectures do not even allow them but rather replace such numbers with zero whenever they occur. Such treatment of subnormals is commonly referred to as a denormals-are-zero (DAZ) policy. And while some architectures handle subnormals, they do so only in software or microcode and at a substantial performance penalty.
The default (lossy) zfp implementation might struggle with blocks composed of all-subnormal numbers, as the numeric transformations involved in compression and decompression might then cause values to overflow and invoke undefined behavior (see Issue #119). Although such blocks are in practice reconstructed as all-subnormals, precision might be completely lost, and the resulting decompressed values are undefined.
One way to resolve this issue is to manually force all-subnormal blocks
to all-zeros (assuming the floating-point hardware did not already do this).
This denormals-are-zero policy is enforced when enabling
ZFP_WITH_DAZ at compile time.
Warning
ZFP_WITH_DAZ can mitigate difficulties with most but not all
subnormal numbers. A more general solution has been identified that will
become available in a future release.
Note
zfp’s reversible-mode compression algorithm handles subnormals correctly, without loss.
Performance¶
There is a negligible compression performance penalty associated with
ZFP_WITH_DAZ.
Execution Policy¶
All execution policies support ZFP_WITH_DAZ.
Portability¶
Because subnormals are modified before compression, the compressed stream
could in principle change when forcing blocks to be encoded as all-zeros.
While compressed streams with and without this setting may not match
bit-for-bit, the impact of ZFP_WITH_DAZ tends to be benign.
In particular, this setting has no impact on decompression. Thus, all
combinations of ZFP_WITH_DAZ between producer and consumer are
safe.
Testing¶
ZFP_WITH_DAZ affects only extremely rare subnormal values that
do not partake in the vast majority of zfp unit tests. Tests are unlikely
to be impacted by enabling this setting.